Splitting PDFs with a Logic App and a Python Function

Recently, I’ve been working with Form Recognizer, a new Azure Cognitive Service that leverages AI and machine learning to extract data from form-based documents. Typically, form-based documents are saved as multi-page PDF files that have been digitally scanned. In this post, I’ll explain how we can leverage a Logic App and a Function App to split apart multi-page PDF files in preparation for sending them to the Form Recognizer service.
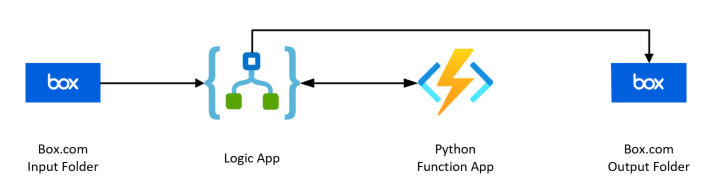
Solution Architecture
In this example, the workflow will be the following:
- User uploads multi-page PDF to a Box.com folder
- Logic App is triggered, sending multi-page PDF data to Function App
- Function App splits apart the multi-page PDF and returns encoded data for each single-page PDF
- Logic App writes each single-page PDF to a separate Box.com folder
For me, the tricky part in this workflow is handling the PDF data - binary, base64, encoded, decoded - there are a lot of options!
If you’d just like to check out the code for the Function App, here is a link to my GitHub.
Here is a quick overview of the steps in the Logic App:

The trigger that will kick-off the execution of the Logic App is when a file is created in a Box.com folder called Input. When this happens, the Logic App will gather metadata for the uploaded file that we will leverage in later steps.
Once we have the metadata for the uploaded file, we get the actual content of the file using the file’s unique identifier (file ID). We pass two parameters in the body of our HTTP request to the Function App - the file’s content and the file’s name. Here’s how we do that:
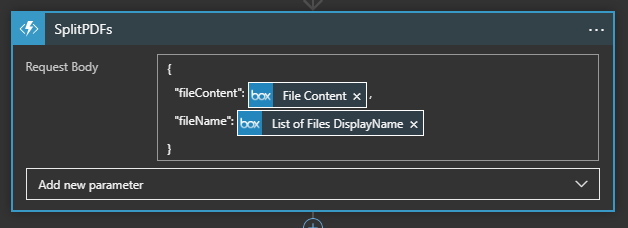
From our Function App, this is how we parse the request body:
req_body = req.get_json()
file_name = req_body.get('fileName')
file_content = req_body['fileContent']['$content']
Now, the file_content variable holds a base64-encoded version of the multi-page PDF that was uploaded into our Input folder in Box.com. In order to make use of this data, we need to do a trick:
file_data = base64.decodebytes(file_content.encode())
First, we encode the file_content variable, and then decode the bytes using the base64 package. And finally, to make this variable play nice with the PyPDF2 package, we use the io package represent the bytes as an input stream, which can be read by PyPDF2.
Then, in the next few code blocks, we create a new PDF file for each page in the original file (you can grab the entire Function App code here). We temporarily write each individual out to the local execution disk, and then read the data back in, encode the data in base64 and then finally decode the base64-encoded data.
file_data = base64.b64encode(temp_pdf_file.read()).decode()
This is the reverse of the steps we took to parse the original, multi-page PDF and is what allows us to transfer the individual PDF data back through HTTP.
At the end of our Function App code, we have a JSON variable containing a list of fileName and fileContent pairs, like below:
{
"individualPDFs": [
{
"fileName": "MyPDF_1_2020-03-05-19-14-23.pdf",
"fileContent": "Base64 Encoded String"
},
{
"fileName": "MyPDF_2_2020-03-05-19-14-23.pdf",
"fileContent": "Base64 Encoded String"
}
]
}
Now, we serialize this JSON object and return this as an HTTP Response to the next step in our Logic App. The next step iterates through each of the individual fileName and fileContent pairs, writing each file to the Output folder in Box.com.
If you’re familiar with Logic App development, there are two development views: the Designer view, which is the drag-and-drop user interface, and the Code View, which is editing the JSON document that represents each step. Below is the JSON for the last step in our Logic App, the For each:
"For_each": {
"actions": {
"Create_file": {
"inputs": {
"body": "@base64ToBinary(items('For_each')?['fileContent'])",
"host": {
"connection": {
"name": "@parameters('$connections')['box']['connectionId']"
}
},
"method": "post",
"path": "/datasets/default/files",
"queries": {
"folderPath": "/Output",
"name": "@{items('For_each')?['fileName']}",
"queryParametersSingleEncoded": true
}
},
"runAfter": {},
"type": "ApiConnection"
}
},
"foreach": "@json(body('SplitPDFs'))['individualPDFs']",
"runAfter": {
"SplitPDFs": [
"Succeeded"
]
},
"type": "Foreach"
}
Of note are lines 5, 15 and 23. Let’s start with line #23:
"foreach": "@json(body('SplitPDFs'))['individualPDFs']"
This line establishes what this step in the Logic App will iterate through. Our Function App returns a JSON object with the field ‘individualPDFs’ containing a list of fileName and fileContent pairs. For every item in this list, the Logic App will write a new file to the Output Box.com folder.
Lines 5 and 15 extract the fileContent and fileName fields for each item in the list we defined in line 23. Here they are below:
"body": "@base64ToBinary(items('For_each')?['fileContent'])"
"name": "@{items('For_each')?['fileName']}"
And that’s it!
Summary
In this post, I’ve detailed how to split a multi-page PDF into single-page PDF documents leveraging Box.com, a Logic App and a Python Function App.